Backend - PAVICS Node¶
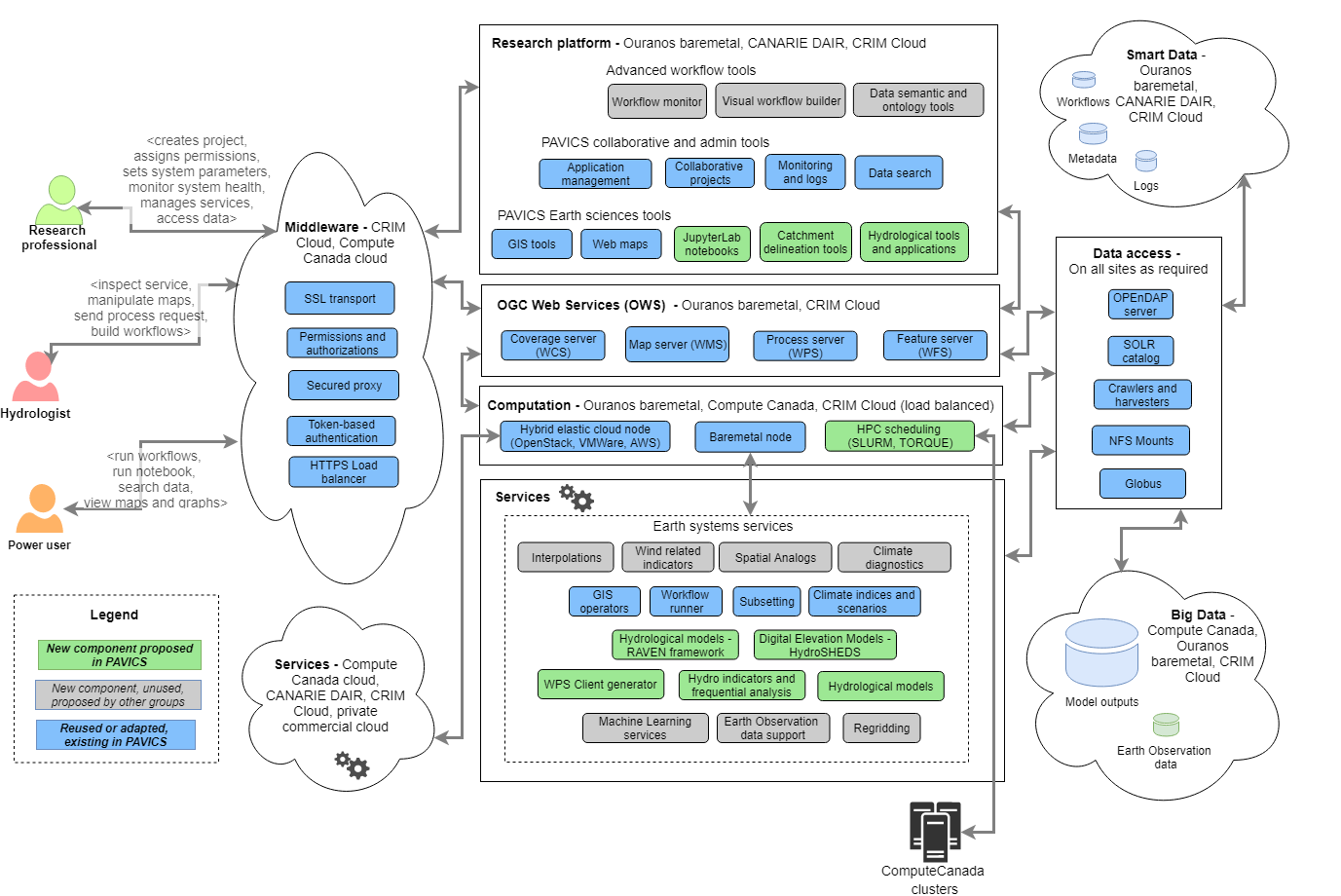
PAVICS nodes are data, compute and index endpoints accessed through the PAVICS platform or external clients. The Node service is the backend that provides data storage, metadata harvesting, indexation and discovery of local and federated data, user authentication and authorization, server registration and management. The node service is therefore composed of several services that are briefly described below, accompanied by links to the full documentation of each individual building block.
The backend of PAVICS-SDI is built entirely with Free and Open Source Software. All of the backend projects (source code and documentation) are open to be inspected, built upon, or contributed to.
Data storage¶
Data is stored on two different servers: THREDDS for gridded netCDF data, and GeoServer for GIS features (region polygons, river networks).
- THREDDS
The Thematic Real-time Environmental Distributed Data Services (THREDDS) is a server system for providing scientific data and metadata access through various online protocols. The PAVICS platform relies on THREDDS to provide access to all netCDF data archives, as well as output files created by processes. The code is hosted on this GitHub repository. THREDDS support direct file access as well as the OPeNDAP protocol, which allows the netCDF library to access segments of the hosted data without downloading the entire file. Links to files archived on THREDDS are thus used as inputs to WPS processes.
- GeoServer
GeoServer is an OGC compliant server system built for viewing, editing, and presenting geospatial data. PAVICS uses GeoServer as its database for vector geospatial information, such as administrative regions, watersheds and river networks. The frontend sends requests for layers that can be overlayed on the map canvas. See the GeoServer documentation for more information on its capabilities.
Data Catalog¶
Although information about file content is stored in the netCDF metadata fields, accessing and reading those fields one by one takes a considerable amount of time. To improve file discoverability, we manage [intake-esm](https://github.com/intake/intake-esm) catalogs for each data category found within the dataset folder of THREDDS:
biasadjusted
climex
cmip5
forecast
gridobs
reanalysis
stationobs
These catalogs are created by:
walking through all the aggregated datasets found in the THREDDS
Datasetsfolder;calling THREDDS NCML service on each dataset. This returns an XML file storing metadata;
parsing the NCML metadata and creating a catalog description (
json) and a data table (csv).
The resulting catalogs are hosted at https://pavics.ouranos.ca/catalog
Climate Analytic Processes with Birdhouse¶
The climate computing aspect of PAVICS is largely built upon the many components developed as part of the Birdhouse Project. The goal of Birdhouse is to develop a collection of easy-to-use Web Processing Service (WPS) servers providing climate analytic algorithms. Birdhouse servers are called ‘birds’, each one offering a set of individual processes:
{kind=link}
- Birdhouse/Finch
Provides access to a large suite of climate indicators, largely inspired by ICCLIM. Finch Official Documentation Finch also includes processes to subset and average gridded data over bounding boxes or polygons.
- Raven
Provides tools for watershed properties extraction for hydrological modeling.
Virtually all individual processes ingest and return netCDF files (or OPeNDAP links for some processes), such that one process’ output can be used as the input of another process. This lets scientist create complex workflows. By insisting that process inputs and outputs comply with the CF-Convention, we make sure that data is accompanied by clear and unambiguous metadata.
Application Packages and Workflow Processes¶
- Weaver
Provides support of Common Workflow Language (CWL) which can be used to deploy custom processes as Application Packages (Docker containers, Python, JavaScript, etc.), and chain processing into distributed Workflows.
Weaver provides both a Web Processing Service (WPS) and a OGC API – Processes interface.
Furthermore, Weaver can combine other WPS processes as remote providers under its unified OGC API endpoints, offering a centralized access point to any Birdhouse WPS process. Because of this, it can also combine Application Packages, OGC API – Processes and WPS Remote Providers simultaneously into a versatile Workflow definition.
The birdhouse-deploy Weaver Component must be enabled to make it available on the server. An example notebook is provided in Optional Notebooks.
Gridded data visualization¶
The PAVICS platform is not meant as a front-end, but still provides backend services to facilitate data visualization. It provides for each netCDF file in the THREDDS server a WMS endpoint that can be used to display netCDF fields over maps.